
Nadchodzi Newsmax Polska?
Na transponderze Cyfrowego Polsatu pojawiła się plansza testowa HD z kolorowymi pasami. Aktualnie nie wiadomo, jaki kanał ją zastąpi. Możliwe,
Read More
DLA DOMU * DLA FIRMY * DLA CIEBIE
Na transponderze Cyfrowego Polsatu pojawiła się plansza testowa HD z kolorowymi pasami. Aktualnie nie wiadomo, jaki kanał ją zastąpi. Możliwe,
Read More
Podczas posiedzenia 17 czerwca 2026 r. Krajowa Rada Radiofonii i Telewizji podjęła szereg decyzji dotyczących rynku medialnego. Najważniejszą z nich
Read MoreTelewizja Republika rozpoczęła nadawanie w jakości HD na MUX 8, bez zmiany standardu multipleksu na DVB-T2. Sprawdzamy, jak wpłynęło to
Read More
Telewizja Polska uruchomiła nowy kanał FAST TVP Muzyka i Koncerty, który przez całą dobę prezentuje archiwalne koncerty, recitale i wyjątkowe nagrania
Read MoreSerdecznie zapraszamy wszystkie dzieci wraz z rodzinami na Piknik z okazji Dnia Dziecka Widzimy się w sobotę 30 maja na
Read More
W środę 20 maja wystartował Kanał Zero TV – nowy kanał HD. Na antenie pojawiły się m.in. „Poranek Zero” i
Read More
Kanał Zero TV startuje w środę 20 maja od „Poranka Zero” na żywo. Poznaliśmy ramówkę na pierwsze dni nadawania. Znajdują
Read More
Od paru dni testujemy już, nasz autorski silnik danych. Silnik został stworzony do kilku konkretnych widgetów. Na stronie dodaliśmy: Kalkulator
Read More
Abonament RTV znów wzrośnie. KRRiT ogłosiła nowe stawki na 2027 r., a podwyżki odczują zarówno posiadacze radia, jak i telewizora.
Read More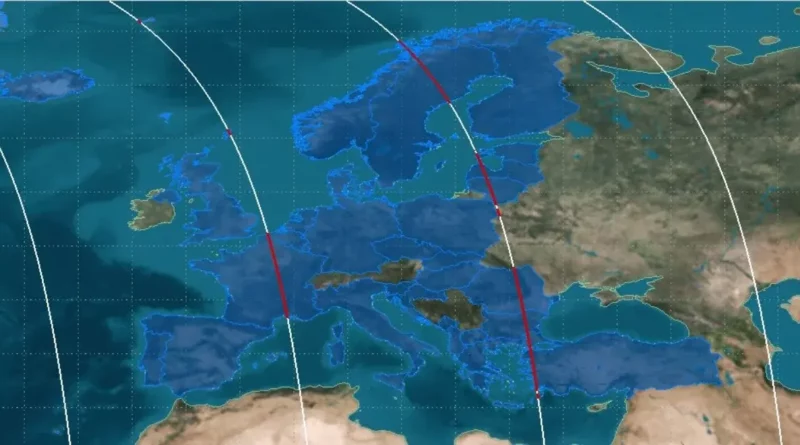
Nad Europą, w tym nad Polską, może przelecieć ważący około 1000 kg fragment rakiety FREGAT. Komunikat w tej sprawie wydała
Read More